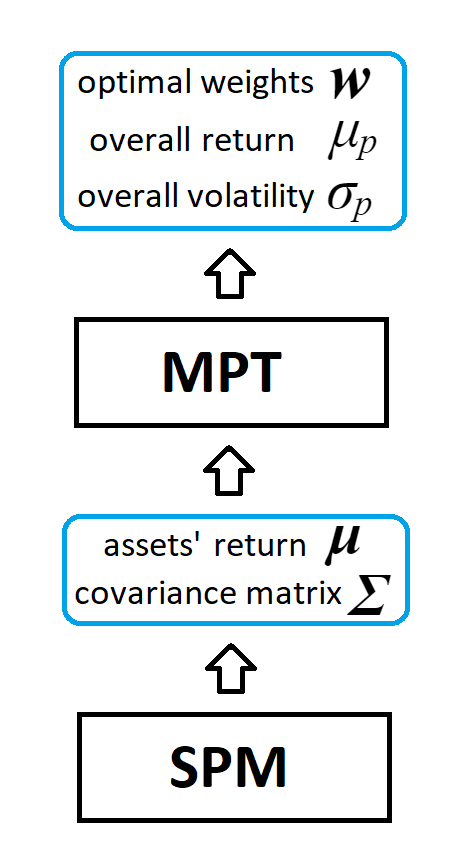
Complementing the Modern Portfolio Theory
The Origin
Key Definitions
| TERMS | DEFINITION |
|---|---|
| Expected Return | μₚ ≔wᵀμ |
| Standard Deviation | σₚ ≔ √(wᵀΣw) |
| Sharpe Ratio | Sₚ ≔ ( μₚ - 1 ) / σₚ if no bond, or Sₚ ≔ ( μₚ - μ₀ ) / σₚ if a bond is included |
| Lever | ℰₚ ≔ ∑|wᵢ|, i ≥ 0, a.k.a. risk exposure |
| Tangency Portfolio | If ∃(Cᵗᶢ > 0) and C ← Cᵗᶢ then w₀ = 0, i.e. zero bond position |
| Non-shortselling Solutions | Exist iff ∃C ∀i wᵢ ≥ 0 |
Two Technical Pillars
Algorithm of finding the extrema
≡ σₚ²·C/2 - μₚ + λ (wᵀ1 - 1)
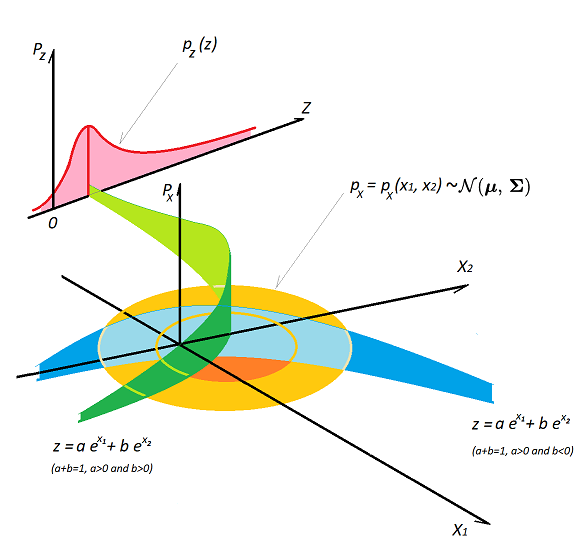
Return Distribution on Maturity